Selenium Xpaths - The secrets revealed!!
What is XPath?
XPath is simply defined as XML path. It is a syntax or language for finding any element on the web page using XML path expression. In another words, the XPath is used to find the location of any element on a webpage using HTML DOM structure. The basic format of XPath is explained below with screen shot.
`

Every element in the DOM does not have an id -> static id, unique name, unique link text. For those elements we need to build xpath to find and then perform actions on them.
Difference between single '/' and double '//'
Single slash '/' anywhere in xpath signifies to look for the element immediately inside the parent element.
Double slash '//' signifies to look for any child or nested-child element inside the parent element.
Syntax for XPath:
XPath contains the path of the element situated at the web page. The Standard syntax for creating XPath is.
Xpath=//tagname[@attribute='value']
- // : Select current node.
- Tagname: Tagname of the particular node.
- @: Select attribute.
- Attribute: Attribute name of the node.
- Value: Value of the attribute.
- ID: To find the element by ID of the element
- Classname: To find the element by Classname of the element
- Name: To find the element by name of the element
- Linked text: To find the element by text of the link
- XPath: XPath required for finding the dynamic element
- CSS path: CSS path also locates elements having no name, class or ID.
Types of X-path
There are two types of XPath:
1) Absolute XPath
2) Relative XPath
Absolute XPath:
It is the direct way to find the element, but the disadvantage of the absolute XPath is that if there are any changes made in the path of the element then that XPath gets failed.
The key characteristic of XPath is that it begins with the single forward slash(/) ,which means you can select the element from the root node.
Below is the example of an absolute xpath expression of the element shown in the below screen.
Absolute xpath:
html/body/div[1]/div[3]/div/div/div/div/div[2]/form/table/tbody/tr[2]/td[1]/input

Coders Tip: Using absolute Xpaths in your Selenium tests is a bad practice since with the evolution of the product, the tag names and the position of the element in the DOM changes which shall inturn break your tests. To mitigate the above situation, it is highly recommended to use Relative Xpaths.
Relative xpath:
For Relative Xpath the path starts from the middle of the HTML DOM structure. It starts with the double forward slash (//), which means it can search the element anywhere at the webpage.
You can start from the middle of the HTML DOM structure and no need to write long xpath.
Below is the example of a relative XPath expression of the same element shown in the below screen. This is the common format used to find element through a relative XPath.
Relative xpath: //*[@class='featured-box']//*[text()='Testing']

XPath Expressions:
Location paths are a subset of a more general concept called XPath expressions. These are statements that can extract useful information from the DOM tree. Instead of just finding nodes, you can count them, add up numeric values, compare strings, and more. They are much like statements in a functional programming language. There are five types, listed here:
- Node Functions
- Numeric Functions
- String Functions
- Boolean Functions
- Namespace Functions
X-Path Node Functions:
A collection of nodes that match an function’s criteria, usually derived with a location path.
- node(): function return node value.
- text(): function return text value of specific node.
- comment(): function matches comment node and return that specific comment node.
- last(): function return size of total context in given context. name of this function last so it's means function not return last node value.
- position(): function return the position of an element in the set (list) of elements in a given context.
- id(dtd_id): function return nodes base on passed DTD unique ID.
- name(node_expression): function return the string name of the last expression (node set).
Numeric Functions:
A numeric value, useful for counting nodes and performing simple arithmetic.- count(node_expression): function count number of element in a specified node.
- sum(node_expression): function return the sum of element value in a specified node.
- div: XPath div function does not take any parameter its you between two numeric functions. and given to a divided value.
- number(): XPath number function converting string to a number.
- floor(): XPath foor function return largest integer round value that is equal to or less then to a parameter value. Another way we can say last round value that value return of the function.
- ceiling(): XPath ceiling function return smallest integer round value that is greater then or equal to a parameter value. Another way we can say next round value that value return of the function.
- round(): XPath round function return the round number of specified nth number of decimal place.
String Functions:
A chunk of text that may be from the input tree, processed or augmented with generated text.
- starts-with(string1, string2)
- text()
- contains(string1, string2)
- substring(string, offset, length?)
- substring-before(string1, string2)
- substring-after(string1, string2)
- string-length(string)
- normalize-space(string)
- translate(string1, string2, string3)
- concat(string1, string2, ...)
1) starts-with(string1, string2)
Key: It returns true when first string starts with the second string.
Thumb-Rule: //<tag-name>[starts-with(@<Attribute-name>,<Value>)]
Thumb-Rule: //<tag-name>[starts-with(@<Attribute-name>,<Value>)]
2) text()
Key: It returns true when string text matches the element text.
Thumb-Rule: //<tag-name>[text(),<Value>)]
Thumb-Rule: //<tag-name>[text(),<Value>)]
3) contains(string1, string2)
Key: It returns true when the first string contains the second string.
Thumb-Rule: //<tag-name>[contains(<Attribute-name/Function-name>,<Value>)]
Thumb-Rule: //<tag-name>[contains(<Attribute-name/Function-name>,<Value>)]
4) substring(string, offset, length?)
Key: It returns a section of the string. The section starts at offset up to the length provided.
Thumb-Rule://<tag-name>[contains(<Attribute-name/Function-name>,substring(<string>,<int offset>,<Optional string length>))]
Thumb-Rule://<tag-name>[contains(<Attribute-name/Function-name>,substring(<string>,<int offset>,<Optional string length>))]
5) substring-before(string1, string2)
Key: It returns the part of string1 up before the first occurrence of string2.
Thumb-Rule://<tag-name>[contains(<Attribute-name/Function-name>,substring-before(<string1>,<string2>))]
Thumb-Rule://<tag-name>[contains(<Attribute-name/Function-name>,substring-before(<string1>,<string2>))]
6) substring-after(string1, string2)
Key: It returns the part of string1 after the first occurrence of string2.
Thumb-Rule://<tag-name>[contains(<Attribute-name/Function-name>,substring-after(<string1>,<string2>))]
Thumb-Rule://<tag-name>[contains(<Attribute-name/Function-name>,substring-after(<string1>,<string2>))]
7) string-length(string)
Key: It returns the length of string in terms of characters.
Thumb-Rule: string-length(//<tag-name>[@Attribute-name/Function-name()='Value'])
Thumb-Rule: string-length(//<tag-name>[@Attribute-name/Function-name()='Value'])
8) normalize-space(string)
Key: It trims the leading and trailing space from string.
Thumb-Rule:normalize-space(//<tag-name>[@Attribute-name/Function-name()=<Value>])
Thumb-Rule:normalize-space(//<tag-name>[@Attribute-name/Function-name()=<Value>])
9) translate(string1, string2, string3)
Key: The translate() function replaces individual characters in one string with different individual characters. The string1 argument is the string whose characters you want to replace; string2 includes the specific characters in string1 that you want to replace; and string3 includes the characters with which you want to replace those string2 characters.
replaces each occurrence of any of the single characters “1,” “2,” or “6,” with the single character “A,” “B,” or “X,” respectively. The value returned from this function call would thus be the string “AB2345X7890.”
Like normalize-space(), the translate() function can be valuable in ensuring that two strings are equal, especially when their case — upper vs. lower — is possibly different, even though they’re otherwise apparently identical. Instead of comparing the two strings directly, compare their case-folded values using
translate( ). Thus:
Every lowercase “a” in something is replaced with a capital “A,” every “b” with a “B,” and so on. Characters in something that don’t match any characters in string2 appear unchanged in the result.
Note that the lengths of
string2 and string3 are usually identical but don’t need to be. If string2 is longer than string3, translate( ) serves to remove characters from string1. So:
removes from
somestring all lowercase letters, while:
uppercases all lowercase letters in
somestring in the first half of the alphabet and removes all those appearing in the second half. If somestring is “VW mini-bus,” this returns the string “VW MII-B”: the uppercase letters “VW” (uppercase letters don’t appear in string2, so they’re passed unchanged), a space, the uppercased “mi” and “i” from “mini,” the hyphen, and the uppercased “b” from “bus.” The “n” in “mini” and the “us” in “bus” are suppressed.
If for some reason it’s desirable, string3 may be longer than string2. This is not necessary, because the function considers only those characters in string3 up to the length of string2. It’s just like you omitted those characters from string3 in the first place.
10) concat(string1, string2, ...)
Key: The concat() function takes at least two arguments and forges them into a single string. The function provides no padding with whitespace, so if you’re constructing (say) a list of tokens, or a set of words into a phrase or sentence, you’ve got to include the " " characters and perhaps punctuation separating one from the other. For instance, assume that the context node at a given point is any of the relic elements in the sample XML document. Then:
Boolean Functions:

Coders Tip: //child::* shall return all elements in the DOM
2) Parent Axis:

builds a string consisting of that relic’s price, a space an opening parenthesis, the currency in which the price is represented, and a closing parenthesis. Given our sample document, for the seven relics in question, this would yield the strings (respectively):
| 9.00 (USD) |
| 39.95 (GBP) |
| 70.75 (EU) |
| .37 (GBP) |
| 323.65 (USD) |
| 8500.00 (USD) |
Note that the figures 9.00, .37, and 8500.00 do not follow the rules outlined above for representing numeric values as strings. If for some reason you want to force this representation, you need to explicitly convert the
price element nodes’ string-values to numbers (using the number( ) function discussed later), pass this result to string(), and finally, pass that function’s result to concat() as its first argument. Like this:
Also note in this case that the call to
string( ) is optional. Because concat( ) expects a string-type argument, it does any necessary conversion automatically.Boolean Functions:
XPath Boolean functions are used for convert argument(as number, string) to a boolean and return either True or False.
1) boolean(number|string|node-expression|object): function convert to it’s argument to a boolean.
Possible condition :
- number returns True if number value does not zero, NaN, negative.
- string returns True if string length does not zero.
- node-expression returns True if node-expression referred node does not empty. object convert into dependent type.
- object convert into dependent type.
2) not(): not function returns true, If it’s argument is false. Otherwise return false.
3) true(): true() function returns true if passed string is a normal string.
4) false(): false() function returns false if passed string is not a normal string.
5) lang(): lang() function returns true if context node language same as specified string argument.
Namespace Functions:
These functions let you determine the namespace characteristics of a node.- local-name(): Returns the name of the current node, minus the namespace prefix.
- local-name(...): Returns the name of the first node in the specified node set, minus the namespace prefix.
- namespace-uri(): Returns the namespace URI from the current node.
- namespace-uri(...): Returns the namespace URI from the first node in the specified node-set.
- name(): Returns the expanded name (URI plus local name) of the current node.
- name(...): Returns the expanded name (URI plus local name) of the first node in the specified node-set.
XPath Parent, Child and Grandparent Concepts:
The XPath Axes :
XPath has 13 different axes, which we shall go through in this section. An XPath axis directs the XPath processor to the “direction” in which to head in as it navigates around the node hierarchical tree(HTML Code).
Xpath axis:
Xpath axis:
1) self: Which contains only the context node
2) ancestor: contains the ancestors of the context node, that is, the parent of the context node, its parent, etc., if it has one.
3) ancestor-or-self: contains the context node and its ancestors
4) attribute: contains all the attribute nodes, if any, of the context node
5) child: contains the children of the context node
6) descendant: contains the children of the context node, the children of those children, etc.
7) descendant-or-self: contains the context node and its descendants
8) following: contains all nodes which occur after the context node, in document order
9) following-sibling: Selects all siblings after the current node
2) ancestor: contains the ancestors of the context node, that is, the parent of the context node, its parent, etc., if it has one.
3) ancestor-or-self: contains the context node and its ancestors
4) attribute: contains all the attribute nodes, if any, of the context node
5) child: contains the children of the context node
6) descendant: contains the children of the context node, the children of those children, etc.
7) descendant-or-self: contains the context node and its descendants
8) following: contains all nodes which occur after the context node, in document order
9) following-sibling: Selects all siblings after the current node
10) namespace: contains all the namespace nodes, if any, of the context node
11) parent: Contains the parent of the context node if it has one
12) preceding: contains all nodes which occur before the context node, in document order
11) parent: Contains the parent of the context node if it has one
12) preceding: contains all nodes which occur before the context node, in document order
13) preceding-sibling: contains the preceding siblings of the context node
1) Child Axis:
Key: The Child Axis defines the child of the context node.
Thumb-Rule: //Child::<tag-name>
Returns the matching element in DOM starting from the first element matching the tag-name from the root.
Example Xpath: //child::div

Coders Tip: //child::* shall return all elements in the DOM
2) Parent Axis:
Key: The parent axis contains only a maximum of one node. The parent node may be either the root node or an element node.
The root node has no parent; therefore, when the context node is the root node, the parent axis is empty. For all other element nodes the parent axis contains one node.
Thumb-Rule: <Xpath>/parent::<tag-name>
Returns the parent element of the context node(the xpath specified in Blue).
Xpath: //input[@id='pass']/parent::td

33) Following Axis:
Key: Following axis contains all nodes after the node marked node that are after the context node in document order.
Thumb-Rule: <Xpath>/following::<tag-name>
Returns the following element of the context node(the xpath specified in Blue).
Xpath: //input[@id='pass']/following::td

4) Following-Sibbling Axis:
Key: The following-sibling axis selects those nodes that are siblings of the context node(at the same level in the DOM)
Thumb-Rule: <Xpath>/following-sibling::<tag-name>
Returns the node after the context node(the node for the Xpath above in Blue)
Xpath: //*[@id='b-getorpost']/following-sibling::a

5) Preceding Axis:
Key: Preceding axis contains all nodes before the node marked node that are after the context node in document order.
Thumb-Rule: <Xpath>/Preceding::<tag-name>
Returns the following element of the context node(the xpath specified in Blue).
Example Xpath: //input[@id='pass']/preceding::td

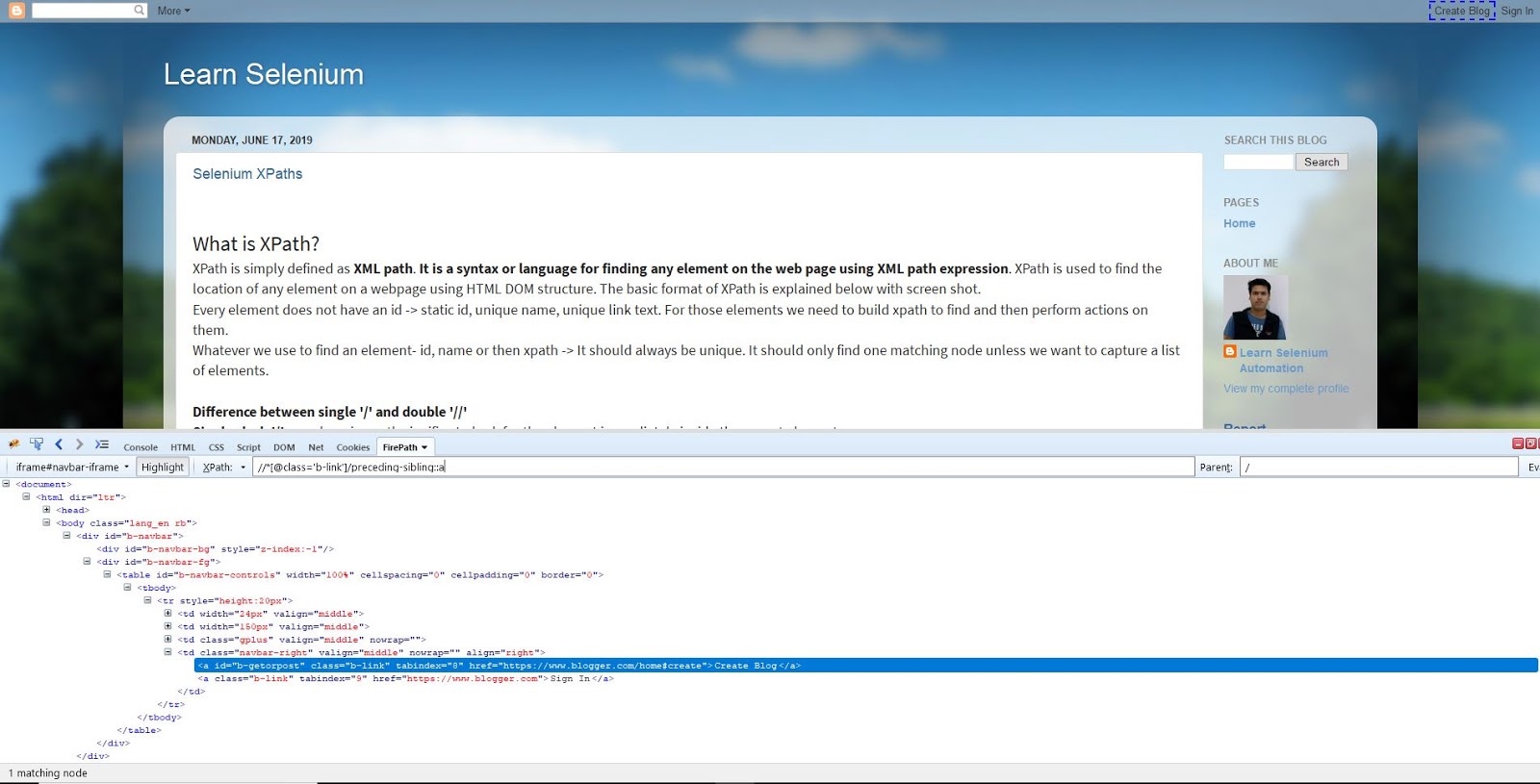
6) Preceding-Sibling Axis:
Key: The following-sibling axis selects those nodes that are siblings of the context node(at the same level in the DOM)
Thumb-Rule: <Xpath>/preceding-sibling::<tag-name>
Returns the node before the context node(the node for the Xpath above in Blue)
Xpath: //*[@class='b-link']/preceding-sibling::a

No comments:
Post a Comment