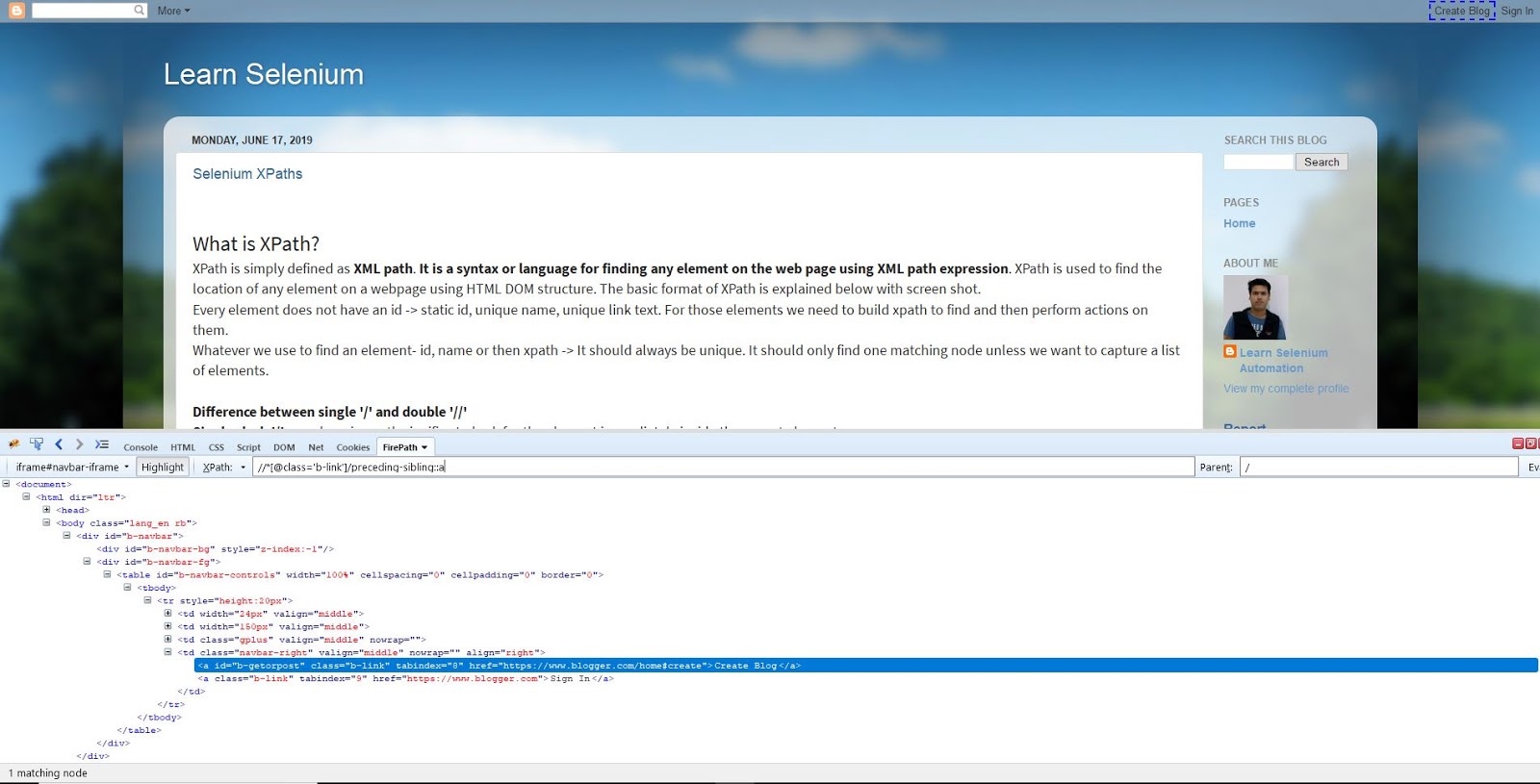
How to Perform Right click in Selenium?
Hi Friends, many a time, in our automation, we may need to right click or context click an element. Later, this action is followed up by pressing the UP/DOWN arrow keys and ENTER key to select the desired context menu element
For right clicking an element in Selenium, we make use of the Actions class. The Actions class provided by Selenium Webdriver is used to generate complex user gestures including right click, double click, drag and drop etc.
Right Click using Actions Class:
Actions action = new Actions(driver);
WebElement ele= driver.findElement(By.id("Log in"));
action.contextClick(ele).perform();
Here, we are instantiating an object of Actions class. After that, we pass the WebElement to be right clicked as parameter to the contextClick() method present in the Actions class. Then, we call the perform() method to perform the generated action.
Sample code to right click an element
package LearnSelenium;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.interactions.Actions;
public class RightClick {
public static void main(String[] args) throws InterruptedException{
WebDriver driver = new FirefoxDriver();
//Launching WebPage to Perform Right Click
driver.get("http://www.facebook.com");
//Right click in the TextBox to enter the Email for Login
Actions action = new Actions(driver);
WebElement searchBox = driver.findElement(By.id("email"));
action.contextClick(searchBox).perform();
//Thread.sleep just for user to notice the event
Thread.sleep(4000);
//Closing the driver instance
driver.quit();
}
}